GPT божеволіє, навчаючись на своїх текстах: дослідження

Група фахівців із двох американських університетів провела дослідження поведінки популярних комерційних моделей AI. Висновок був несподіваний і дуже тривожний…
Виявилося, що AI-мережі, навчені на основі власних даних або даних інших систем штучного інтелекту в якийсь момент починають “божеволіти”. Як результат, отримані користувачем дані (зображення, тексти тощо) не відповідають реальності.
Постає питання: як можна (і чи можна?) виправити ситуацію?
Дослідження
Фахівці Університету Райса та Стенфордського Університету виявили обмеження систем AI (наприклад, таких як ChatGPT та Midjourney). Дослідження показало, що мережі штучного інтелекту починають божеволіти після п’яти ітерацій генерації даних.
Вчені навіть запровадили для цього явища спеціальний термін – MAD (скорочення від Model Autophagy Disorder, аутофагічний розлад системи). Простіше кажучи, модель, навчена на даних AI, починає “поїдати саму себе”. Виявляється, справа в тому, що штучний інтелект просто ігнорує дані, що перебувають на краях так званої кривої Белла (вона ж функція Гаусса) і починає видавати певний усереднений результат.
Простіше кажучи. Крива Белла – це дзвоноподібна крива, де по центру (на вершині) зосереджена основна кількість усереднених значень.
“У роботі… ми питаємо себе: що відбувається, коли ми навчаємо нові генеративні моделі на даних, які частково генеруються попередніми моделями. Ми показуємо, що генеративні моделі втрачають інформацію про справжній розподіл, а модель зводиться до середнього представлення даних”, – написав у твіттері спеціаліст у галузі машинного навчання Ніколас Пейпернот, член дослідницької групи
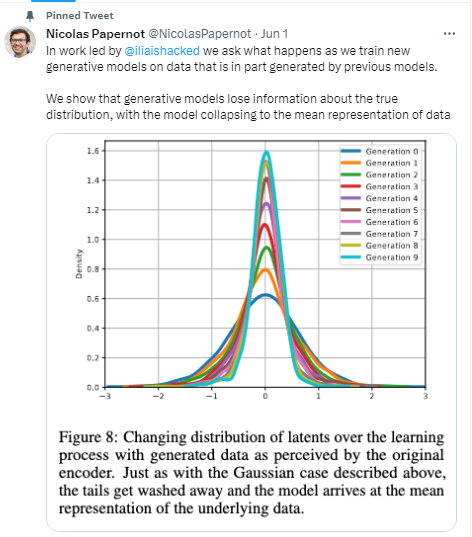
Що показало дослідження? Джерело: Twitter
Як встановили науковці, приблизно після п’яти “раундів” обробки інформації AI, дані на краях кривої зникають взагалі.
“Вони (дослідники – ред.) дивляться, що відбувається, коли ви навчаєте генеративні моделі на їхніх власних вихідних даних… знову і знову. Моделі зображень витримують 5 ітерацій, перш ніж відбуваються дивні речі”, – пояснив Том Гольдштейн, професор УМД (безпека та конфіденційність ШІ, алгоритмічний ухил, основи машинного навчання). Саме на цьому етапі починається MAD.
Як доказ Гольдштейн показав, що відбувається із зображеннями, після послідовної обробки штучним інтелектом.
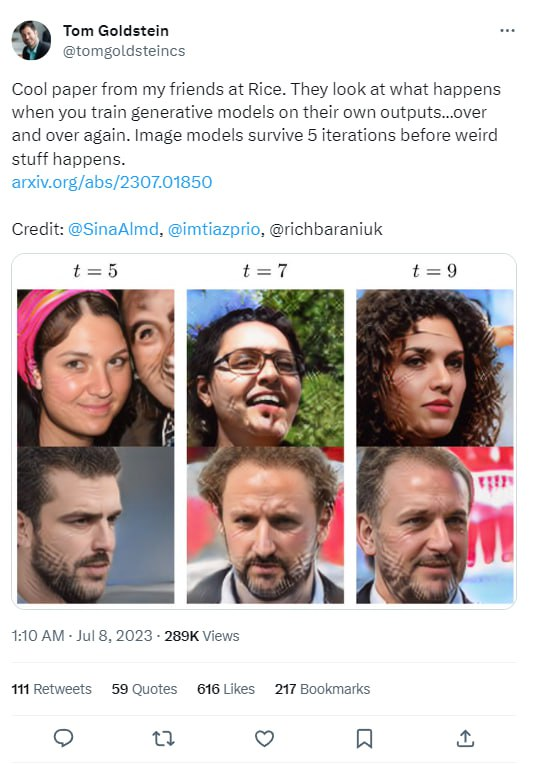
Як лагає GPT Джерело: Twitter
Номери (див. Картинку вище) означають кількість ітерацій. Ми можемо наочно спостерігати, як АI поступово зводить фото певного індивіда до усередненого зображення.
Наскільки серйозною є проблема MAD?
Дослідники стверджують, що явище аутофагії спостерігається на всіх моделях та платформах AI. Також воно було помічене і на багатьох автокодировщиках і LLM (великих мовних моделях). Це саме ті моделі, які мають найбільшу популярність серед користувачів. Тож, якщо ваш ChatGPT від OpenAI або AI Claude від Anthropic почне “чудити” – видавати незрозумілі тексти чи некоректні зображення – не дивуйтесь.
Тут варто згадати ступінь поширення систем AI у корпоративній, громадській сферах та особистому користуванні. На штучний інтелект “зав’язано” багато процесів управління виробництвом, інтернетом речей, обробки інформації тощо. Усі сфери навести, мабуть, уже неможливо.
Де знайти психіатрів для GPT?
Здавалося б, проблема багато в чому надумана – просто обмежте кількість ітерацій та не доводьте свій АI до MAD. А розробники наступних модифікацій врахують це явище.
Але не все так просто, як стверджують дослідники. У мережі з’явилося безліч немаркованих продуктів AI. Їхня кількість щодня стрімко зростає, нарощуючи швидкість.
Просто перенавчати існуючі системи традиційним методом? Для AI це означатиме лише черговий “раунд”, який лише погіршить ситуацію.
При цьому звичайні методи перевірки результату (текст, зображення, шумозаглушення тощо) пошуковими системами нічого не дадуть. Користувач ніколи не знатиме, що перед ним – оригінальний продукт чи продукт AI.
Водночас не можна просто “закидати” системи AI новою перевіреною оригінальною інформацією. На загальному тлі вона неминуче потрапить на краї кривої Белла і буде проігнорована. Тому питанням №1 для нової інформації, що заливається в мережу, стають водяні знаки, які ідентифікують контент AI.
Є ще варіант різкого збільшення у всесвітній павутині кількості релевантної інформації. За рахунок зростання частоти результатів по краях кривої Белла, AI поступово “затягуватиме” правдиву інформацію до вершини графіка (тобто до середніх результатів). Краї, як і раніше, обрізатимуться, але AI почне використовувати нові перевірені дані. Науковці назвали це рішення методом зміни вагових коефіцієнтів.
Втім, тут починаються нові проблеми. Як змінити ці коефіцієнти? Хто візьметься за це титанічне завдання? При внесенні нових масивів даних знову знадобиться перевірка релевантності результатів, що видаються AI. Також доведеться вивчити оновлені налаштування системи та зрозуміти, чи спрацював цей підхід.
Та ви ж і самі мало не збожеволіли, дочитавши цю статтю до кінця, чи не так?:)


