GPT сходит с ума, обучаясь на своих текстах: исследование

Группа специалистов из двух американских университетов провела исследование поведения популярных коммерческих моделей AI. Вывод был неожиданным и весьма тревожным…
Оказалось, что AI-сети, обученные на основе собственных данных или данных других систем искусственного интеллекта в какой-то момент начинают “сходить с ума”. В результате, полученные пользователем данные (изображения, тексты и пр.) не отражают реальности.
Возникает вопрос: каким образом можно (и можно ли?) исправить ситуацию?
Исследование
Специалисты Университета Райса и Стэнфордского Университета обнаружили ограничения систем AI (например, таких как ChatGPT и Midjourney). Исследование показало, что сети искусственного интеллекта начинают сходить с ума после пяти итераций генерации данных.
Ученые даже ввели специальный термин для этого явления - MAD (сокращение от Model Autophagy Disorder, аутофагическое расстройство системы). Попросту говоря, модель, обученная на данных AI, начинает “поедать саму себя”. Выражается это в том, что искусственный интеллект просто игнорирует данные, находящиеся на краях т.н. кривой Белла (она же функция Гаусса) и начинает выдавать некий усредненный результат.
Простым языком. Кривая Белла – это колоколообразная кривая, где по центру (на вершине) сосредоточена основная масса усредненных значений.
“В работе… мы задаемся вопросом: что происходит, когда мы обучаем новые генеративные модели на данных, которые частично генерируются предыдущими моделями. Мы показываем, что генеративные модели теряют информацию об истинном распределении, а модель сводится к среднему представлению данных” - написал в твиттере специалист в области машинного обучения Николас Пейпернот, член исследовательской группы.
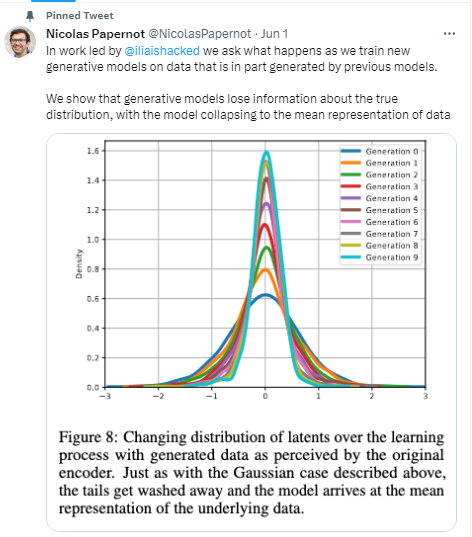
Что показало исследование? Источник: Twitter
Как установили ученые, примерно после пяти “раундов” обработки информации AI, данные на краях кривой исчезают вообще.
“Они (исследователи - ред.) смотрят, что происходит, когда вы обучаете генеративные модели на их собственных выходных данных… снова и снова. Модели изображений выдерживают 5 итераций, прежде чем происходят странные вещи” - пояснил Том Гольдштейн, профессор УМД (безопасность и конфиденциальность ИИ, алгоритмический уклон, основы машинного обучения). Именно на этом этапе и начинается MAD.
В качестве доказательства Гольштейн показал, что происходит с изображениями, после последовательной обработки искусственным интеллектом.
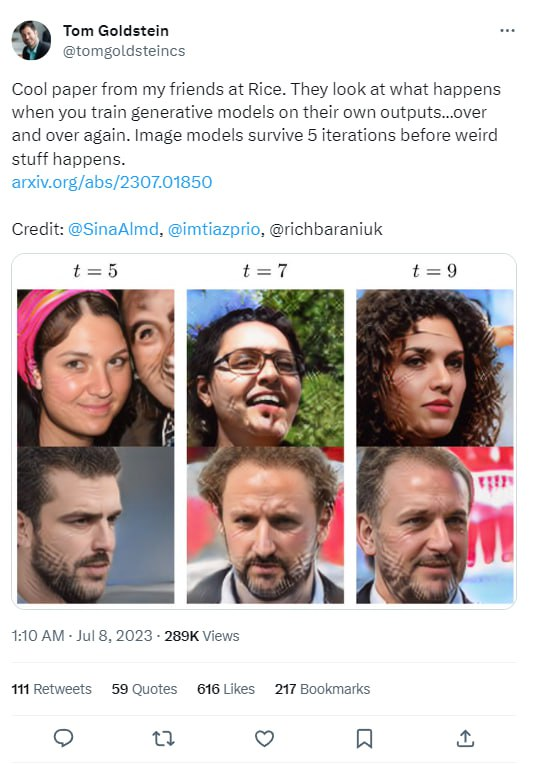
Как лагает GPT Источник: Twitter
Номера (см. Картинку выше) обозначают количество итераций. Мы можем наглядно наблюдать, как АI постепенно сводит фото определенного индивидуума к некому усредненному изображению.
Насколько серьезна проблема MAD?
Исследователи утверждают, что явление аутофагии наблюдается на всех моделях и платформах AI. Также оно было замечено и на многих автокодировщиках и LLM ( больших языковых моделях). Это именно те модели, которые пользуются наибольшей популярностью у пользователей. Так что если ваш ChatGPT от OpenAI или AI Claude от Anthropic начнет “чудить” – выдавать непонятные тексты или некорректные изображения – не удивляйтесь.
Здесь стоит вспомнить степень распространения систем AI в корпоративной, общественной сферах и личном пользовании. На искусственный интеллект “завязаны” многие процессы управления производством, интернетом вещей, обработки информации и т.д. Все сферы перечислить, наверное, уже невозможно.
Где найти психиатров для GPT?
Казалось бы, проблема во многом надумана - просто ограничьте количество итераций и не доводите свой АI до MAD. А разработчики следующих модификаций учтут это явление.
Но не все так просто, как утверждают исследователи. В сети появилось громадное количество немаркированных продуктов AI. Их количество продолжает увеличиваться каждый день с нарастающей скоростью.
Просто переучивать существующие системы традиционным методом? Для AI это будет означать лишь очередной “раунд”, который только усугубит ситуацию.
При этом обычные методы проверки результата (текст, изображение, шумоподавление и пр.) поисковыми системами ничего не дадут. Пользователь никогда не будет знать, что перед ним - оригинальный продукт или продукт AI.
В то же время, нельзя просто “забрасывать” системы AI новой проверенной оригинальной информацией. На общем фоне она неизбежно попадет на края кривой Белла и будет проигнорирована. Поэтому вопросом №1 для новой информации, заливаемой в сеть, становятся водяные знаки, которые идентифицируют контент AI.
Есть еще вариант резкого увеличения во всемирной паутине количества релевантной информации. За счет роста частоты результатов по краям кривой Белла, AI будет постепенно “затягивать” правдивую информацию к вершине графика (то есть к средним результатам). Края будут по-прежнему обрезаться, но AI начнет использовать новые проверенные данные. Ученые назвали это решение методом изменения весовых коэффициентов.
Впрочем, тут начинаются новые проблемы. Как изменить эти коэффициенты? Кто возьмется за эту титаническую задачу? При внесении новых массивов данных опять потребуется проверка релевантности результатов, выдаваемых AI.Также придется изучить обновленные настройки системы и понять, сработал ли этот подход.
Да вы ведь и сами чуть не сошли с ума, дочитав эту статью до конца, верно?:)


